Der Befehl muss in der Datenbank Master ausgeführt werden, ansonsten steht dieser nur in der Datenbank zur Verfügung, in der das Skript ausgeführt wurde, da nur dort sp\_whoisactive als Stored Procedure gespeichert wird.
Nun steht der Befehl in allen Datenbanken zur verfügung und kann einfach in einer beliebigen SQL-Query ausgeführt werden mit `sp_whoisactive`. Eine vollständige Dokumentation des Befehls ist hier zu finden: [sp\_whoisactive Doku](https://jaeckel.one/attachments/70) ### sp\_who2 Um die aktiven Verbindungen eines SQL-Servers einsehen zu können, kann der Befehl `sp_who2` verwendet werden. Es können mehrere Verbindungen pro Rechner und User sein. Deswegen empfiehlt es sich folgende Abfrage zu verwenden, um die Informationen etwas aufzubereiten. ```sql CREATE TABLE #sp_who2 ( SPID INT,Status VARCHAR(255) ,Login VARCHAR(255) ,HostName VARCHAR(255) ,BlkBy VARCHAR(255) ,DBName VARCHAR(255) ,Command VARCHAR(255) ,CPUTime INT ,DiskIO INT ,LastBatch VARCHAR(255) ,ProgramName VARCHAR(255) ,SPID2 INT ,REQUESTID INT ) INSERT INTO #sp_who2 EXEC sp_who2 SELECT Login ,HostName ,DBName ,Command ,ProgramName ,COUNT(*) AS Verbindungen ,SUM(CPUTime) AS CPUTime ,SUM(DiskIO) AS DiskIO ,MAX(LastBatch) AS LastBatch FROM #sp_who2 WHERE SPID > 50 AND DBName = 'Testdatenbank' GROUP BY Login ,HostName ,DBName ,Command ,ProgramName ORDER BY Login ASC DROP TABLE #sp_who2 ``` Der Befehl sp\_who2 wurde um eine temporäre Tabelle erweitert, in welche die ermittelten Daten geschrieben werden. Dadurch steigt zwar der Aufwand für die Ausführung, jedoch können die Daten so sinnvoller gefiltert werden, da sonst sehr viele Daten dargestellt werden. In diesem Beispiel werden einige Systemprozesse ausgeschlossen und nur Verbindungen zur Datenbank *Testdatenbank* angezeigt. Zusätzlich wird gruppiert, um mehrfache Verbindungen zusammenzufassen. # Einzelbenutzer Modus Für einige administrative Tätigkeiten kann es sinnvoll sein, die Datenbank in den sog. _Single-User Mode_ zu versetzen. In diesem Modus kann nur ein User mit der Datenbank interagieren. Eine bestimmte Datenbank in den _Single-User Mode_ versetzen: ```sql ALTER DATABASE N'Sollte das Wiederherstellen fehlschlagen, weil noch aktive Verbindungen bestehen, dann kann die Datenbank zeitweise in den Einzelbenutzer Modus geschaltet werden.
Soll das Backup auf einem anderen Server wiederhergestellt werden, so sind das Vollbackup und alle darauf folgenden gesicherten Transaktionslogs in das Backupverzeichnis des Zielservers zu übertragen. Anschließend kann wie unten gezeigt das Backup wiederhergestellt werden.
# Restore eines Vollbackups Dies ist der einfachste Fall, eine Datenbank wird einfach aus einer .bak Datei wiederhergestellt. Dies geht einfach und schnell. 1. Microsoft SQL Server Management Studio öffnen und in Server einloggen 2. Rechtsklick auf _Databases_ -> _Restore Database..._ 3. Danach folgende Schritte umsetzen (1 - 5) 1. im Reiter _General_ unter _Source_ von _Database:_ auf _Device:_ wechseln 2. die 3 Punkte auswählen 3. mit _Add_ den Dialog zum Auswählen der Backup Datei öffnen 4. den Order der Backups auswählen 5. die Backup Datei auswählen und mit _OK_ bestätigen [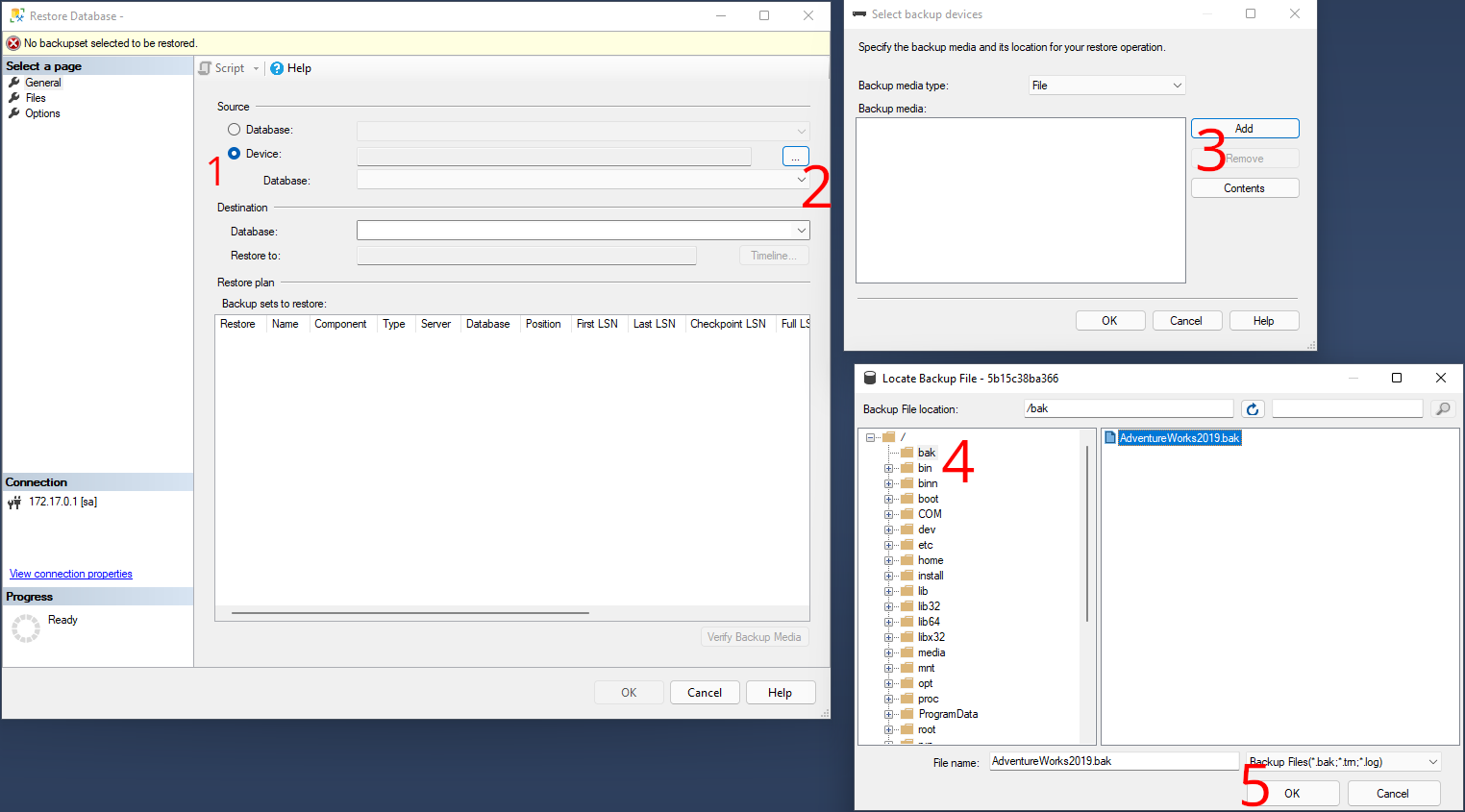](https://jaeckel.one/uploads/images/gallery/2024-04/image-1711989175010.png) 4. Es wird nun ein _Backup media:_ angezeigt, dieses nochmal mit _OK_ bestätigen. 5. Nun wird ein Restore Punkt angezeigt, diesen nur noch mit _OK_ bestätigen und danach steht die Datenbank in der Version zur Verfügung. [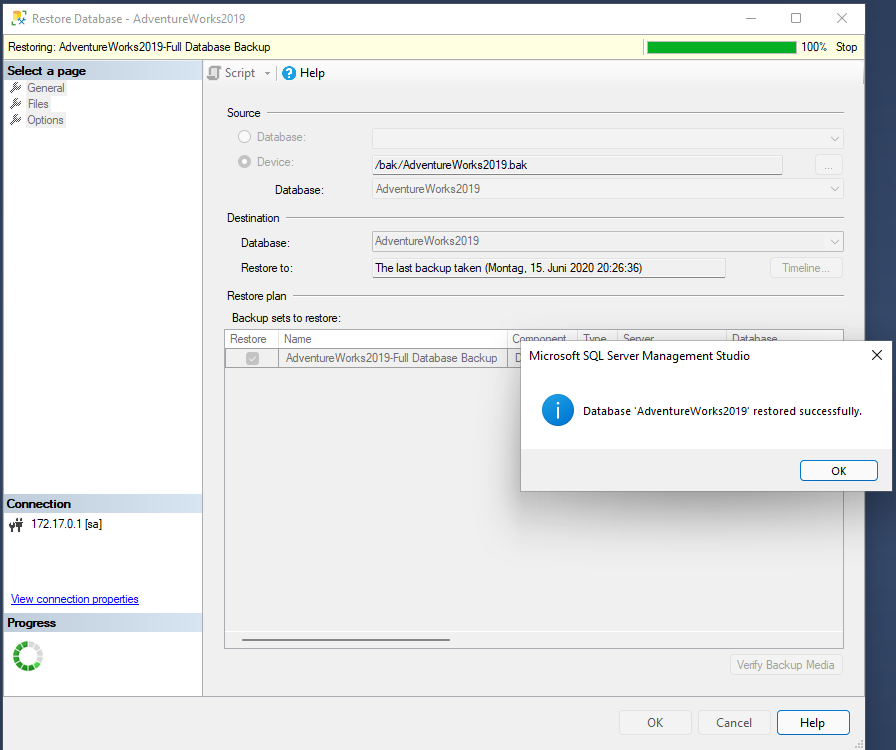](https://jaeckel.one/uploads/images/gallery/2024-04/image-1711989207624.png) # Restore eines Vollbackups mit Logs Dieser Fall ist aufwendiger als der einfache Restore eines Vollbackups, aber es kann fast auf die Minute sogar Sekunde genau wiederhergestellt werden. Bei dieser Art des Restores wird zuerst ein Vollbackup eingespielt, danach werden dann die Transaktionslogs eingespielt. Wird z. B. 1x täglich um 20 Uhr ein Vollbackup erstellt und alle 30 Minuten werden die Log Dateien gesichert und abgeschnitten, so kann beispielsweise die Datenbank von 15:30 Uhr wiederhergestellt werden. Eventuell können sogar die Änderungen auf die Minute z. B. 15:35 Uhr eingespielt werden, sofern der Zeitpunkt exakt bekannt ist und das Transaktionslog nicht beschädigt ist, wie im Fall von gelöschten Datensätzen (denn diese sind dann ordnungsgemäß ins Transaktionslog geschrieben).Egal ob das Backup über das Management Studio oder T-SQL eingespielt wird, in beiden Fällen muss das _Recovery Model_ der Datenbank auf _Simple_ gesetzt werden.
## Mit T-SQL 1. Damit das Vollbackup + Logs zurückgespielt werden kann, ist das _Recovery Model_ der Datenbank auf _Simple_ zu setzen. ```sql USE [master]; ALTER DATABASE [AdventureWorks2019] SET RECOVERY SIMPLE; ``` 2. Nun kann das Vollbackup eingespielt werden, dabei ist insbesondere der Parameter `WITH NORECOVERY` wichtig, da dieser dafür sorgt, dass die Datenbank im Wiederherstellungsmodus bleibt: ```sql RESTORE DATABASE [AdventureWorks2019] FROM DISK = '/backup/FULL/AdventureWorks2019_20230419_171225.bak' WITH NORECOVERY ``` 3. Nun werden der Reihe nach alle gesicherten Transaktionslogs eingespielt: ```sql RESTORE LOG [AdventureWorks2019] FROM DISK = '/backup/LOG/AdventureWorks201920230419_171315.trn' WITH NORECOVERY ``` Dabei ist wichtig, dass solange noch weitere Log Dateien folgen, der Parameter `WITH NORECOVERY` mit übergeben wird. 4. Die letzte Log Datei wird ohne den `WITH NORECOVERY` Parameter eingespielt, damit der Wiederherstellungsprozess ordnungsgemäß beendet wird: ```sql RESTORE LOG [AdventureWorks2019] FROM DISK = '/backup/LOG/AdventureWorks201920230419_171441.trn' ``` ## Mit Management Studio Tatsächlich erfolgt das Wiederherstellen mittels Management Studio genauso wie bei Restore eines Vollbackups. Es ist nur vorher das Recovery Model zu ändern. # TempDB # Größe der TempDB Es können mehrere Dateien zusammen die TempDB bilden z. B. 8x 8MB bei 8 CPU-Kernen. Außerdem ist in der Regel ein automatisches Wachsen eingestellt, sodass die Dateien größer werden, je länger die Laufzeit des Servers. Über das SQL Management Studio können die Größen der Temp-Dateien eingesehen werden, jedoch nicht die initiale Größe: [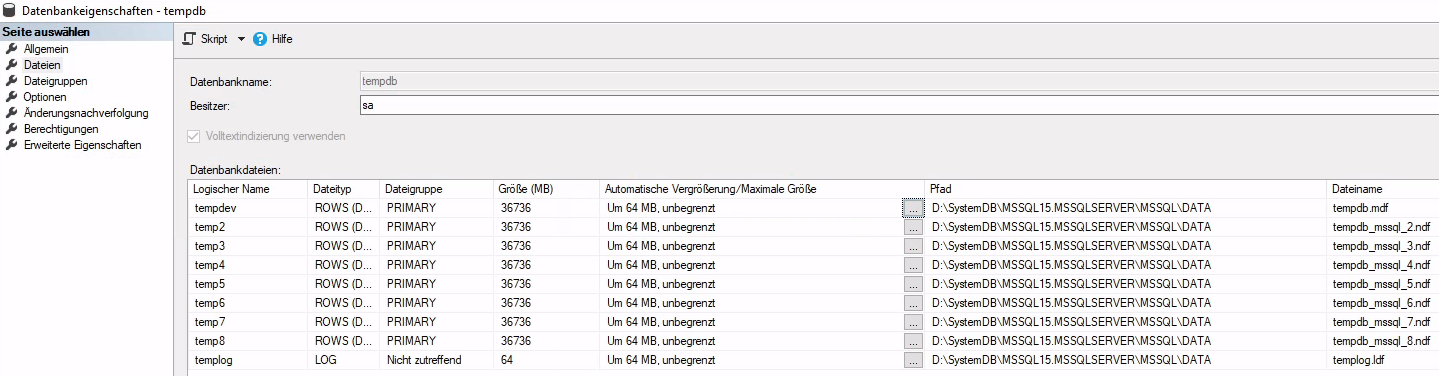](https://jaeckel.one/uploads/images/gallery/2024-04/image-1711989486850.png) # Initialgröße der TempDB-Dateien ändern Die aktuelle Größe der TempDB-Dateien lässt sich nicht ändern, da in diesen Temp-Tabellen usw. gespeichert sind, die der SQL Server benötigt. Jedoch lässt sich die Größe angeben, wie viel Speicherplatz die Dateien beim Start des SQL Server Dienstes aufweisen dürfen. Standardmäßig sind dies 8 MB. Zwar wachsen die Dateien dynamisch mit, jedoch sollte die Anfangsgröße an die benötigte Größe angepasst werden, da jede Vergrößerung Performance kostet. ```sql ALTER DATABASE tempdb MODIFY FILE (Name=tempdev, SIZE = 16GB); ALTER DATABASE tempdb MODIFY FILE (Name=temp2, SIZE = 16GB); ALTER DATABASE tempdb MODIFY FILE (Name=temp3, SIZE = 16GB); ALTER DATABASE tempdb MODIFY FILE (Name=temp4, SIZE = 16GB); ALTER DATABASE tempdb MODIFY FILE (Name=temp5, SIZE = 16GB); ALTER DATABASE tempdb MODIFY FILE (Name=temp6, SIZE = 16GB); ALTER DATABASE tempdb MODIFY FILE (Name=temp7, SIZE = 16GB); ALTER DATABASE tempdb MODIFY FILE (Name=temp8, SIZE = 16GB); ``` Damit die Änderungen wirksam werden, muss der SQL Server Dienst neu gestartet werden. # Initialgrößen der TempDB-Dateien ```sql SELECT name ,size*8.0/1024 'Initial Size in MB' FROM master.sys.sysaltfiles WHERE dbid = 2 ``` # Änderungen mit Change Tracking verfolgen Der MS SQL Server bietet ein Feature mit dem Namen Change Tracking an, welches die Änderungen von Zeilen in einer Tabelle mittels Versionierung verfolgbar machen kann. Im Gegensatz zum Change Data Capture (CDC) werden jedoch nicht die Änderungen an sich erfasst und gespeichert, sondern es wird eine Versionsnummer über die Änderungen vergeben, sodass z. B. nur alle geänderten Abfragen seit einer bestimmten Version zurückgegeben werden können. Dieses Feature bietet sich an, um inkrementelle SQL-Abfragen zu gestalten, da so z. B. jede Stunde ein SELECT ausgeführt werden kann, welches alle geänderten Zeilen zurückgibt, um diese in eine andere Datenbank zu kopieren oder mittels einer BI-Software zu verarbeiten. Damit die Änderungen erfasst werden können, muss zuerst Change Tracking in der Datenbank und dann für die zu überwachenden Tabellen aktiviert werden. Um Change Tracking in einer Datenbank verfügbar zu machen, kann folgendes SQL verwendet werden. ```sql ALTER DATABASE ÄndereDenDatenbanknamen SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 7 DAYS, AUTO_CLEANUP = ON) ``` In diesem SQL wurde eine Verfallszeit von 7 Tagen angegeben und dass die Logs ab dann abgeschnitten werden. Es können auch kürzere oder längere Zeiträume definiert oder sogar das Aufräumen komplett deaktiviert werden. Jedoch können bei vielen Änderungen eine Menge Daten anfallen, sodass ein Aufräumen zu empfehlen ist. Mit dem folgenden SQL kann nun das Tracking für eine Tabelle aktiviert werden. ```sql ALTER TABLE ÄndereDenNamenDerTabelle ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON) ``` Nun werden alle Änderungen in der Tabelle überwacht und führen zu einer Aktualisierung der Version. Außerdem werden auch die Spalten überwacht, sodass nicht nur festgestellt werden kann, welche Zeilen geändert wurden, sondern auch welche Spalten. Diese Option sollte auf OFF gesetzt werden, wenn nur die geänderten Zeilen benötigt werden und sowieso immer bestimmte Spalten oder sogar alle Spalten ausgegeben werden. Die Versionierung startet bei 0 und wird mit jeder Änderung um 1 hochgezählt, die aktuelle Version lässt sich mit folgendem SQL ermitteln. ```sql SELECT CHANGE_TRACKING_CURRENT_VERSION(); ``` Wenn nun Änderungen an den Daten vorgenommen werden, wird die Version automatisch erhöht. Mit Hilfe des folgenden SQL können nun nur die Änderungen ab einer bestimmten Version zurückgegeben werden. ```sql SELECT aenderungen.SYS_CHANGE_VERSION, emp.* FROM CHANGETABLE (CHANGES HumanResources.Employee, 0) AS aenderungen INNER JOIN HumanResources.Employee emp on emp.[BusinessEntityID] = aenderungen.[BusinessEntityID]; ``` Als Beispiel wurde die Tabelle *HumanResources.Employee* aus der AdventureWorks Beispieltabelle verwendet. Hier wurde die Version auf 0 gesetzt, wodurch alle Zeilen zurückgegeben werden, welche jemals verändert wurden (innerhalb der letzten 7 Tage, da diese die Löschzeit ist). Nachdem das Change Tracking aktiviert wurde, sind 2 Zeilen in der Tabelle verändert worden, wodurch die Abfragen nun folgende Ergebnisse liefern. [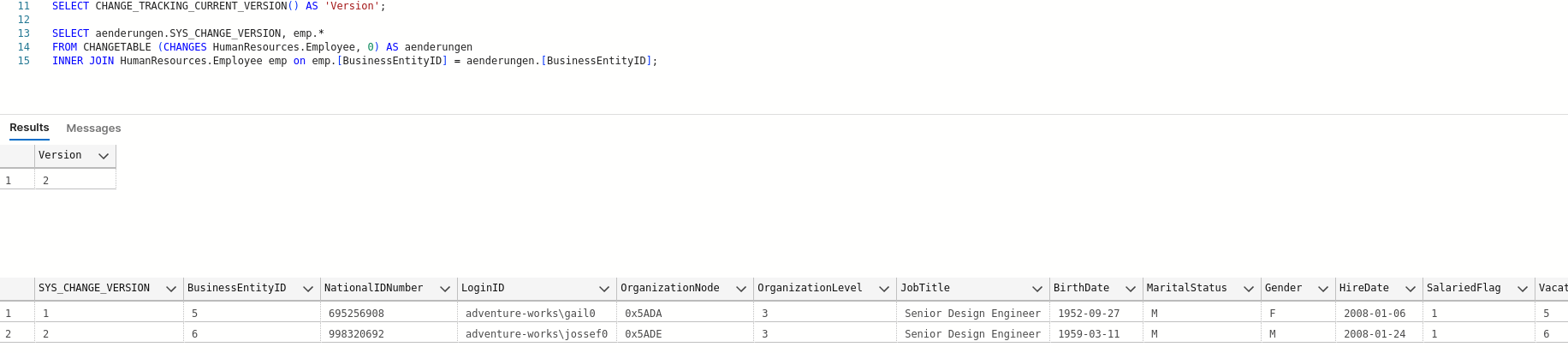](https://jaeckel.one/uploads/images/gallery/2024-04/Qyegrafik.png)