Metabase
Ein Reporting Tool zum selber hosten. Es stellt einen Webserver mit grafischer Benutzeroberfläche bereit. Es lassen sich eigene Datenquellen anbinden und darauf aufbauend Berichte erstellen mit schönen bunten Grafiken wie geografischen Karten, Balken- und Kuchen-Diagrammen, dynamischen Filtern usw.
Auch die Daten dieser Bookstack Instanz (PostgreSQL) lassen sich mit Metabase analysieren, ein öffentlich freigegebenes Dashboard gibt es hier: https://data.jaeckel.one/public/dashboard/6264254d-c80a-4aed-86ea-1af040f86f4f
- Funktionen im Überblick
- Installation
- Ersteinrichtung
- Datenquelle hinzufügen
- Erste Datenabfrage
- Beispieldaten
- Abfragen über mehrere Datenbanken
Funktionen im Überblick
In diesem Kapitel werden einige Funktionen gezeigt. Hierbei geht es nicht darum, wie die Funktionen realisiert werden, sondern was möglich ist.
Datenbankquellen
Metabase unterstützt eine Vielzahl an Datenbanken als Quellen für die Abfragen.
Folgende Datenbanken werden offiziell unterstützt:
- Amazon Athena
- BigQuery (Google Cloud Platform)
- Druid
- MongoDB (recommend version 4.2 or higher)
- MySQL (recommend version 8.0.33 or higher, as well as MariaDB version 10.4 or higher)
- Oracle
- PostgreSQL
- Presto
- Redshift (Amazon Web Services)
- Snowflake
- SparkSQL
- SQL Server
- SQLite
- Vertica
Zusätzlich gibt es noch von Partnern und der Community gepflegte Treiber: https://www.metabase.com/docs/latest/developers-guide/partner-and-community-drivers#community-drivers
Unter anderem sind es folgende Datenbanken:
Visueller Abfrage Designer
Der visuelle Abfrage Designer (Visual Query Builder) ermöglicht das erstellen von Abfragen, ohne die Abfragesprache eintippen zu müssen. Es können Tabellen grafisch miteinander verbunden werden (Join). Es können verschiedene Aggregatsfunktionen angewendet werden wie Summen oder Mittelwerte (AVG, MAX). Es lassen sich Filter definieren, um bei der Anzeige des Reports dynamisch die Daten zu filtern.
Selbstverständlich können trotzdem noch die Abfragen selbst geschrieben werden, so erhält der Benutzer die maximale Freiheit, entweder einfach Klickibunti oder schwierig dafür mit allem was das Herz begehrt.
Dashboards
Die z. B. visuellen Abfrage Designer entworfen Abfragen können in einem Dashboards zusammengestellt werden. Dadurch bekommt der Benutzer eine Übersicht mit allen relevanten Daten. Selbstverständlich lassen sich Filter definieren, die alle Datensätze in dem Dashboard filtern, z. B. auf den aktuellen Monat, um die Top-Kunden dieses Monats zu sehen sowie die Umsätze in den einzelnen Wochen und die Top-Artikel.
Modelle bereitstellen
Es können Modelle bzw. Abfragen erstellt und geteilt werden. Sodass die Benutzer, sofern diesen die Berechtigung erteilt wurde, direkt auf die Datenbasis zugreifen können, um selbst die Daten abfragen und ggf. in ihre eigenen Dashboards einbetten zu können.
Datenbankmodelle
Metabase ist in der Lage selbst das Datenbankmodell zu analysieren. Dabei werden die Datentypen und mögliche Verbindungen zwischen den Tabellen erkannt und in einer eigenen Dokumentation festgehalten. Auch Kommentare, sofern im Datenbankmanagementsystem vorhanden, werden erkannt und mit aufgenommen. Diese Datenbankmodell kann dann in der Oberfläche von Metabase angepasst werden. Das Datenbankmodell verwendet Metabase dann, um die Abfragen für den Benutzer zu designen. Es ist also sehr wichtig, dass das Modell vollständig und richtig ist, damit der grafische Designer gute Ergebnisse liefern kann.

Installation
Folgende Docker Compose Konfiguration kann zur Bereitstellung von Metabase zusammen mit einer Postgres Datenbank als Backend verwendet werden. In Postgres speichert Metabase seine Metadaten, Dashboards, User usw.
services:
metabase:
image: metabase/metabase:latest
container_name: metabase
volumes:
- /dev/urandom:/dev/random:ro
ports:
- 3000:3000
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: metabase
MB_DB_PORT: 5432
MB_DB_USER: metabase
MB_DB_PASS: Ganz-Tolles-Passwort
MB_DB_HOST: postgres
healthcheck:
test: curl --fail -I http://localhost:3000/api/health || exit 1
interval: 15s
timeout: 5s
retries: 5
postgres:
image: postgres:latest
container_name: postgres
environment:
POSTGRES_USER: metabase
POSTGRES_DB: metabase
POSTGRES_PASSWORD: Ganz-Tolles-Passwort
volumes:
- /path/to/data:/var/lib/postgresql/dataUm die Docker Compose Konfiguration auszuführen, kann am besten in das Verzeichnis der YAML Datei gewechselt werden. Danach wird je nach nach gewählter Installation sudo docker-compose up -d oder sudo docker compose up -d (keine Bindestrich zwischen docker und compose) eingegeben, um die Standard Konfiguration docker-compose.yml zu starten. Compose erstellt dann die gewünschten Container mit den angegeben Optionen. Sollten die Container bereits mit dieser Compose Konfiguration erstellt worden sein, so werden die Container in dieser neu erstellt, dessen Konfiguration geändert wurde.
Nach 1 bis 2 Minuten ist Metabase bereit und kann über http://Server-IP:3000 aufgerufen werden.
Ersteinrichtung
Wenn Metabase das 1. Mal geöffnet wird, führt ein Assistent den Benutzer durch die ersten notwendigen Schritte, wie Administrationsuser anlegen und ggf. eine 1. Datenquelle hinzufügen (es können später natürlich noch Datenquellen hinzugefügt werden).
Zuerst erscheint eine freundliche Begrüßung, bei der auf Lass uns loslegen geklickt wird.

Anschließend wird die Sprache ausgewählt.

Nach einem Klick auf Nächste ist ein Administrator anzulegen, welche für die weitere Konfiguration von Metabase benötigt wird. Dieser Benutzer darf alles in Metabase.

Nachdem die Daten eingetragen wurden auf Nächste klicken. Es folgt ein Dialog, um eine erste Datenquelle mit aufzunehmen. Dieser Schritt ist optional und kann erstmal übersprungen werden. In der Administration lassen sich später noch die Datenquellen hinzufügen. Dazu unter der Schaltfläche Zeige mehr Optionen auf den etwas unscheinbaren Text Ich füge meine Daten später hinzu klicken.
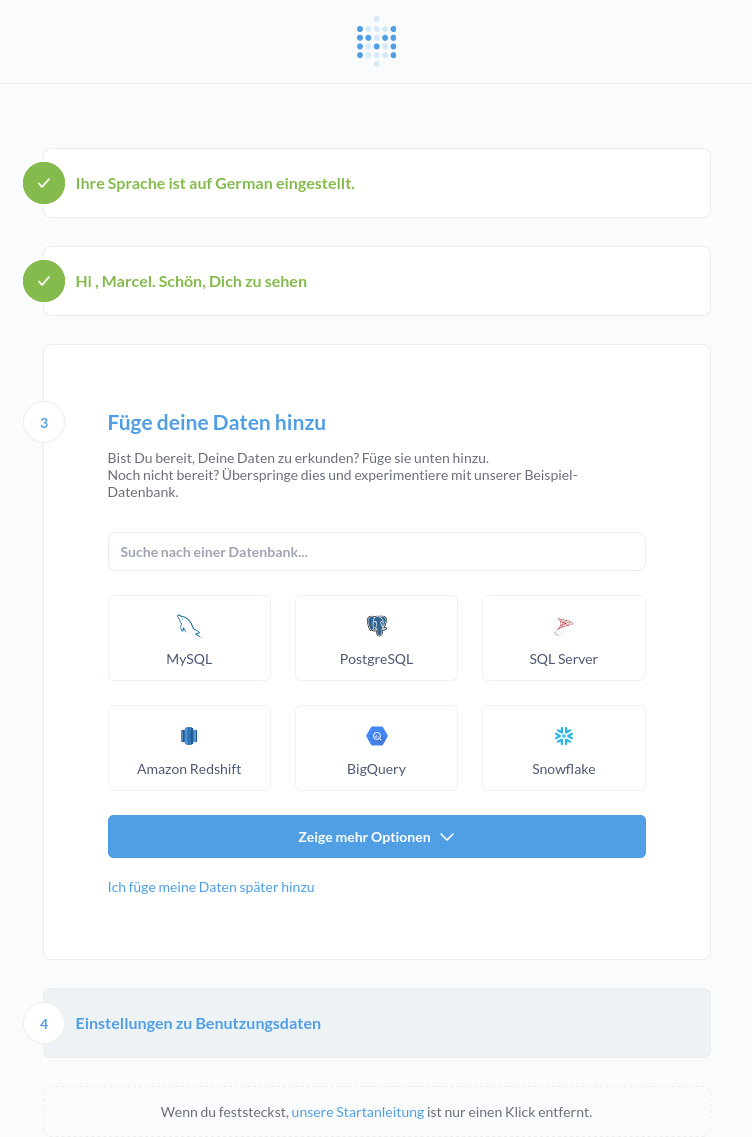
Nun muss noch die Frage beantworten werden, ob das anonyme Sammeln von Ereignisinformationen zugelassen werden darf und auf Beenden klicken.

Zum Schluss nur noch festlegen, ob der Newsletter von Metabase abonniert werden soll, falls nicht, einfach auf Führe mich zu Metabase klicken.

Datenquelle hinzufügen
Datenquellen sind die Grundlage für alle Abfragen. Eine Datenquelle repräsentiert eine Datenbank.
Metabase unterstützt verschiedene Datenbanktypen, u. a. folgende:
- Amazon Athena
- Amazon Redshift
- BigQuery
- Druid
- MongoDB
- PostgreSQL
- Presto
- Snowflake
- Spark SQL
- SQL Server
- SQLite
Die Datenquellen können nur von Administratoren verwaltet werden. Um eine Datenquelle hinzuzufügen, wird das Administrationsmenü von einem Admin aufgerufen. Zuerst rechts oben auf das Zahnrad klicken und anschließend auf Admin Einstellungen.
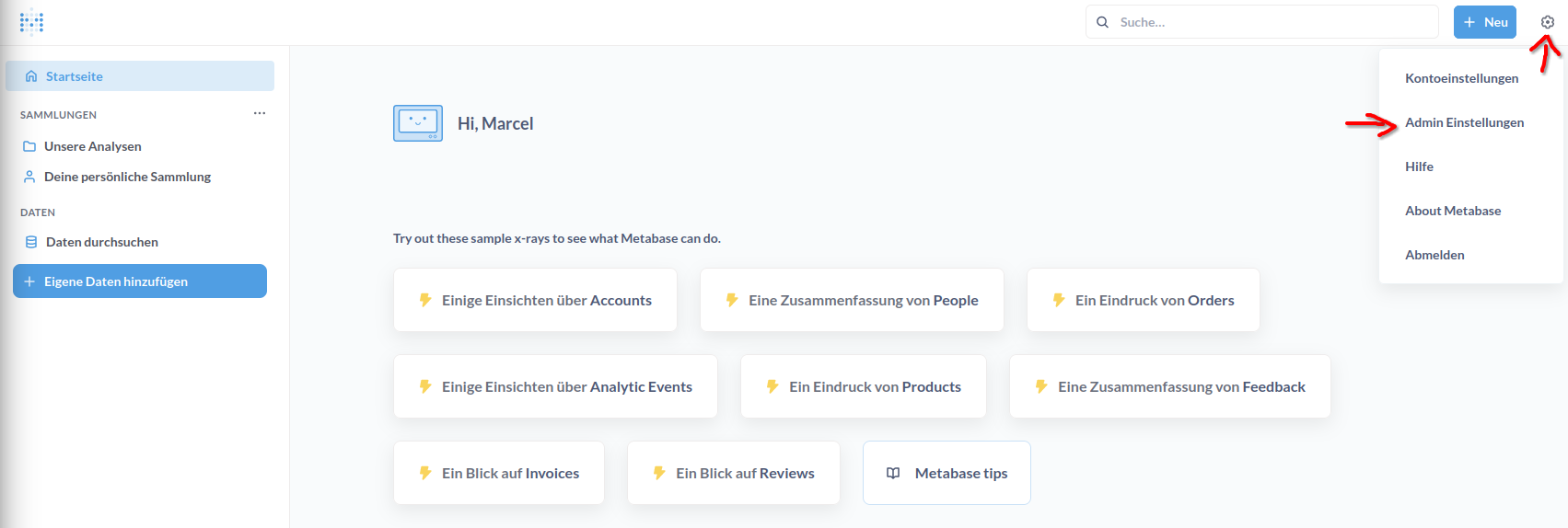
Nun wechselt die Anzeige in den Administrator. Dort wird nun oben in der Menüleiste auf Datenbanken geklickt, um diese zu verwalten. Im Screenshot ist bereits eine Datenbank vorhanden, hierbei handelt es sich um die Beispieldatenbank von Metabase, welche jeder frischen Installation hinzugefügt wird. Wir wollen nun eine neue Datenbank anbinden, also klicken wir auf Datenbank hinzufügen.

Je nachdem welcher Datenbanktyp ausgewählt ist, werden die datenbankspezifischen Parameter abgefragt. In diesem Beispiel wird die MariaDB (sehr ähnlich zu MySQL ,somit wird der Datenbanktyp MySQL verwendet) von Bookstack angebunden. Sobald auf Speichern geklickt wird, speichert Metabase die Verbindung als Datenbank und analysiert die Daten, um verschiedene Metadaten zu generieren, damit diese für die Erstellung von Abfragen verwendet werden können.

Nachdem die Datenbank nun hinzugefügt wurde und ein wenig Geduld (je nach Größe der Datenbank und je nach Datenbanktyp etwas mehr) können die Metadaten über Tabellen-Metadaten eingesehen werden.

In diesem Menü wird links oben die Datenbank ausgewählt, dessen Tabellen betrachtet werden soll. Nun werden alle Tabellen dieser Tabelle angezeigt und mit einem Klick auf eine Tabelle können alle Metadaten von dieser betrachtet werden.

Doch die Metadaten lassen sich nicht nur anschauen, sondern können auch bearbeitet werden. So kann die Sichtbarkeit geändert werden, um z. B. unnötige oder sensible Spalten generell auszublenden. Über das kleine Zahnrad neben den Spalten stehen noch mehr Optionen zur Auswahl, wie z. B. das Datenformat. Weiterhin können Beschreibungen hinzugefügt werden, was vor allem bei Spalte hilfreich ist, die schlecht beschrieben sind oder nicht eindeutig zuzuordnende Daten enthalten.
Nun kann die Administration verlassen werden, um mit der Erstellung von Abfragen und Dashboards zu beginnen.
Erste Datenabfrage
Sobald die 1. Datenquelle hinzugefügt wurde, ist es Zeit für die 1. Abfrage. Um Daten aus der Datenquelle zu fördern, stehen 2 Möglichkeiten zur Auswahl (später 3, sobald Modelle erstellt wurden): Frage und SQL Abfrage. Dazu oben rechts auf Neu klicken und die gewünschte Option auswählen. Für den Anfang sind nur Frage und SQL Abfrage interessant, die anderen Optionen spielen erst später eine Rolle.

Frage
Hierbei handelt es sich um den einfachsten Weg, um Daten aus den Quellen zu fördern und darzustellen. Es wird eine grafische Oberfläche geöffnet, die zuerst nach der Datenquelle fragt, welche die Grundlage für die Datenabfrage ist.
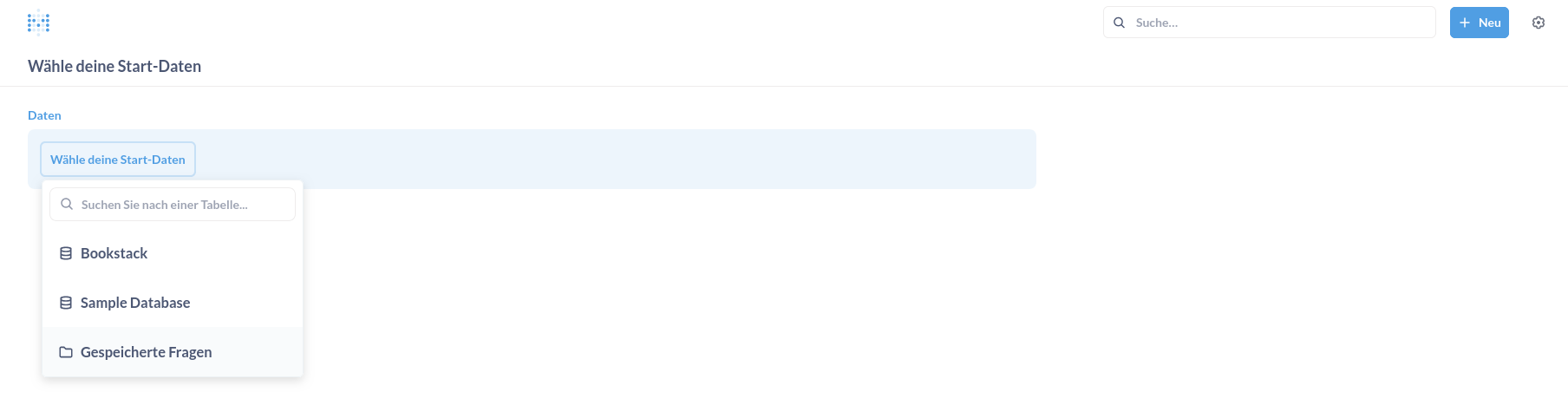
Wird die Quelle ausgewählt, zeigt Metabase direkt die Tabellen und Views an, welche in der Datenquelle zur Verfügung stehen. Hier bietet es sich an, die Suche oberhalb der Ergebnisse zu nutzen, insbesondere bei vielen Tabellen, wie in diesem Fall.

Nachdem eine Tabelle gewählt wurde, wechselt die UI, sodass nun die Tabelle als Grundlage für weitere Einstellungen gesetzt ist. Nun stehen diverse weitere Optionen zur Auswahl wie z. B. Joins, um weitere Tabellen mit dieser Tabelle zu verknüpfen. Wird hierbei zuerst die Tabelle ausgewählt, welche einen Referenzschlüssel auf die Join-Tabelle enthält, kann Metabase die Schlüssel selbst erkennen und setzen. Im folgenden Beispiel wurde als Basis-Tabelle die Zwischentabelle zum Verbinden der Shelves mit den Books ausgewählt. Anschließend wurde lediglich die Tabelle ausgewählt und Metabase hat selbstständig die zu setzenden Schlüssel erkannt.

Nun lassen sich diverse Aufbereitungen der Daten vornehmen, rechts wird neben jedem Schritt ein kleiner Play-Button angezeigt, mit dem die Daten angezeigt werden können, so lassen sich sehr schön die Daten ansehen, nachdem diese manipuliert wurden.
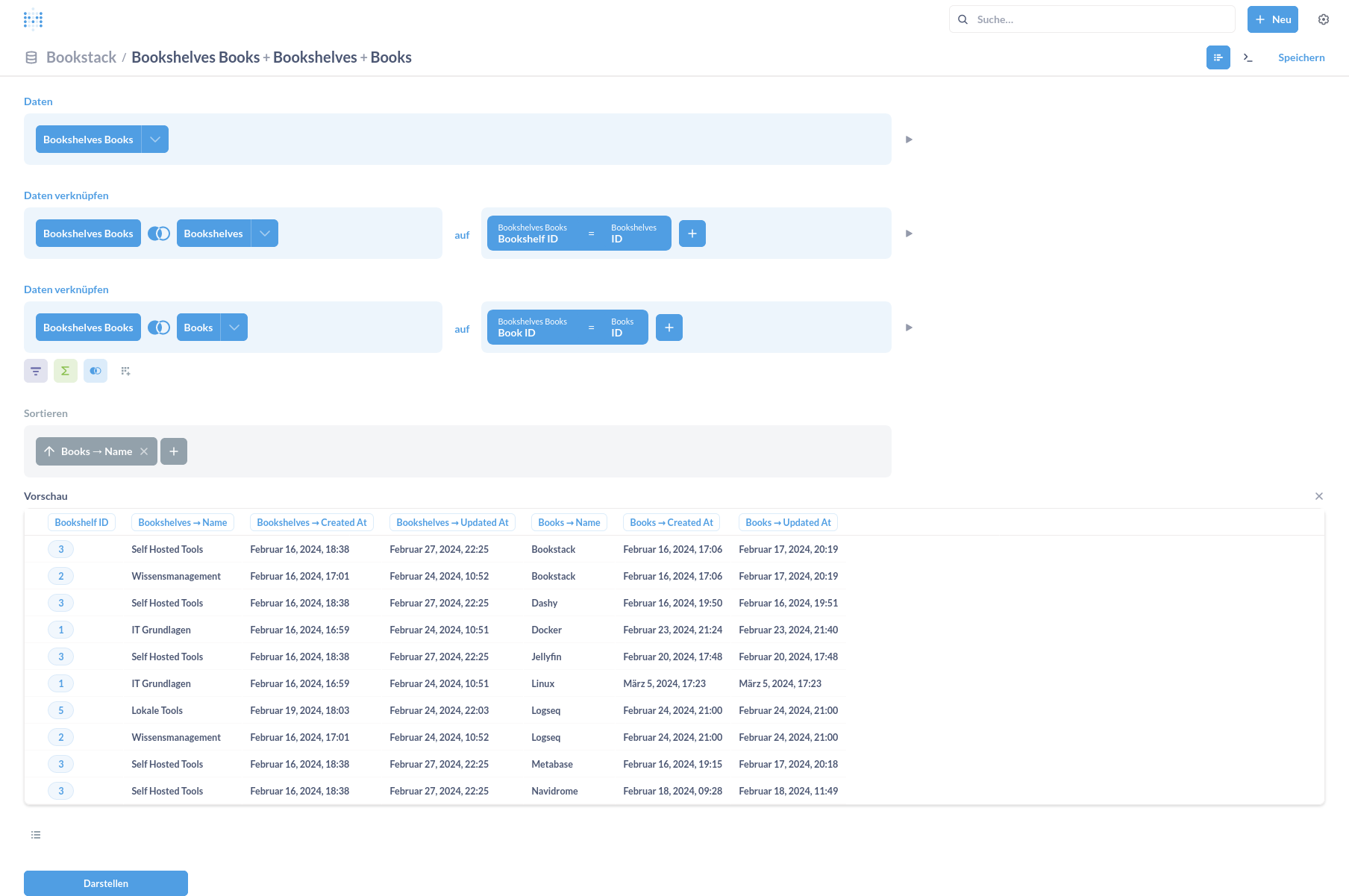
Im Beispiel oben wurden die Daten z. B. sortiert und wie im nächsten Screenshot zu sehen, können auch Spalten ausgeblendet werden.

Beispieldaten
Wer gerade keine ordentliche Datenbank samt Testdaten zur Hand hat, kann z. B. die AdventureWorks Beispiele von Microsoft herunterladen und in den eigenen Microsoft SQL Server wiederherstellen.
Die .bak Dateien können hier heruntergeladen werden: https://learn.microsoft.com/en-us/sql/samples/adventureworks-install-configure?view=sql-server-ver16&tabs=ssms#download-backup-files
Zuerst wird eine Docker Compose Datei erstellt, welche die Konfiguration des SQL-Servers vornimmt.
services:
sql:
image: mcr.microsoft.com/mssql/server:2022-latest
container_name: sql
environment:
- ACCEPT_EULA=Y
- MSSQL_SA_PASSWORD=EinNichtSoTolles08.15Passort
- MSSQL_BACKUP_DIR=/var/opt/mssql/backup
- MSSQL_LOG_DIR=/var/opt/mssql/log
volumes:
- /pfad/zu/sql/data:/var/opt/mssql/data
- /pfad/zu/sql/log:/var/opt/mssql/log
- /pfad/zu/sql/backup:/var/opt/mssql/backupNun werden die 3 Ordner für die Daten, Logs und Backups erstellt. Mit dem folgenden Skript werden auch direkt die Rechte angepasst (bitte den Pfad in der Variable anpassen).
cd /pfad/zu/sql/
mkdir data log backup
sudo chown -R 10001 data log backupUm die Docker Compose Konfiguration auszuführen, kann am besten in das Verzeichnis der YAML Datei gewechselt werden. Danach wird je nach nach gewählter Installation sudo docker-compose up -d oder sudo docker compose up -d (keine Bindestrich zwischen docker und compose) eingegeben, um die Standard Konfiguration docker-compose.yml zu starten. Compose erstellt dann die gewünschten Container mit den angegeben Optionen. Sollten die Container bereits mit dieser Compose Konfiguration erstellt worden sein, so werden die Container in dieser neu erstellt, dessen Konfiguration geändert wurde.
Während der SQL-Server startet, kann die bak-Datei der AdventureWorks in den Ordner /pfad/zu/sql/backup heruntergeladen werden. Eine Übersicht mit allen verfügbaren Sicherungsdateien inklusive Downloads gibt es hier: AdventureWorks-Beispieldatenbanken
Wer es automatisieren möchte, kann es auch mittels folgender Bash-Zeile herunterladen.
cd /pfad/zu/sql/backup
wget https://github.com/Microsoft/sql-server-samples/releases/download/adventureworks/AdventureWorks2022.bakSobald der SQL-Server gestartet und bereit ist, kann das Backup mit folgendem Befehl eingespielt werden.
sudo docker exec -it sql /opt/mssql-tools/bin/sqlcmd \
-S localhost -U SA -P 'EinNichtSoTolles08.15Passort' \
-Q 'RESTORE DATABASE AdventureWorks2022 FROM DISK = "/var/opt/mssql/backup/AdventureWorks2022.bak" WITH MOVE "AdventureWorks2022" TO "/var/opt/mssql/data/AdventureWorks2022.mdf", MOVE "AdventureWorks2022_Log" TO "/var/opt/mssql/data/AdventureWorks2022.ldf"'Nun steht eine SQL-Server Instanz samt AdventureWorks2022 Datenbank zum Spielen bereit.
Abfragen über mehrere Datenbanken
Metabase kann keine Abfragen über Tabellen aus mehreren Datenbanken erstellen. In einigen Servern können zwar Workarounds gebaut werden, wie z. B. beim Microsoft SQL Server (siehe Linked Servers), jedoch sind diese Lösungen auch nicht so schön.
Jedoch kann mit dem Tool Presto (https://jaeckel.one/books/presto) eine zusätzliche Schicht zwischen Metabase und den Datenbanksystemen geschaffen werden. Presto sammelt dann die Daten von den Systemen ein und übergibt sie in Form einer Datenschnittstelle an Metabase. In Presto wird hierzu ein sog. Catalog erstellt, welcher dann als eine Datenbank in Metabase eingebunden werden kann. Der Catalog wiederum enthält die Abfragen, welche sich aus verschiedenen Datenbanksystemen bilden.
Diese Abfragen werden dann in Metabase wie Tabellen dargestellt, sodass sich komfortabel die UI und der mächtige Designer von Metabase verwenden lassen. Die Komplexität der Abfragen wird in Presto vor den Anwendern versteckt.
Durch diese Zwischenschicht können in Metabase somit Datenquellen zusammengeführt werden. Zusätzlich lassen sich hierdurch auch die Zugriffe leichter verwalten, da nur die Views in dem Catalog in Metabase zur Verfügung stehen, aber nicht direkt die Datenquellen darunter.
Wie so eine View für Metabase erstellt werden kann, lässt sich hier nachlesen: https://jaeckel.one/books/presto/page/view-erstellen (Es wird eine funktionierende Presto Instanz vorausgesetzt.)
Der in Presto erstellte Catalog lässt sich in Metabase wie jede andere Datenbank hinzufügen.
Ach wenn in Presto keine Authentifizierung angegeben wurde, so muss trotzdem der Benutzer angegeben werden. Im Standard ist dies der Benutzer presto und ohne Passwort.
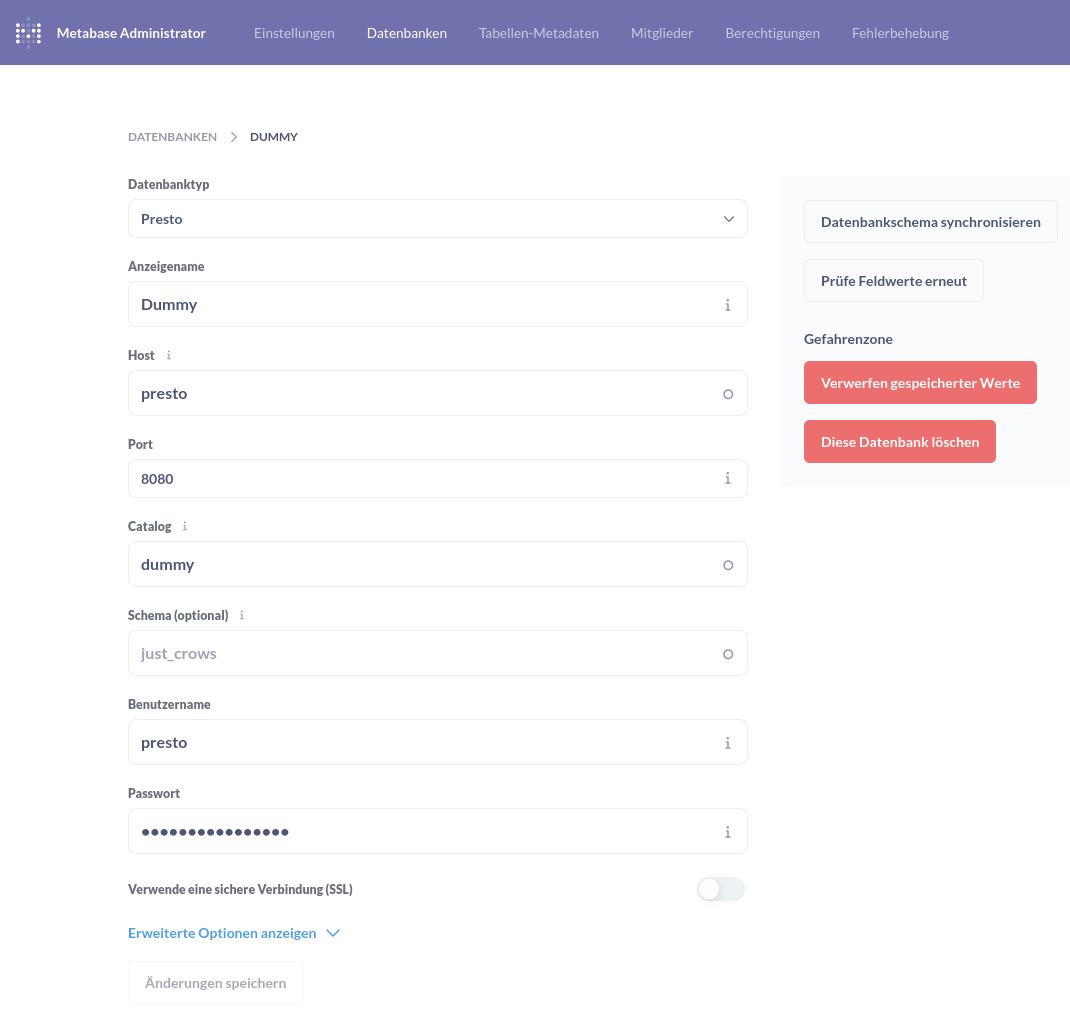
Nachdem die Datenbank hinzugefügt wurde, lassen sich die Views wie gewohnt abfragen. Im folgenden Beispiel ist die View DiesIstEineView aus dem Beispiel der Presto Anleitung zu sehen.
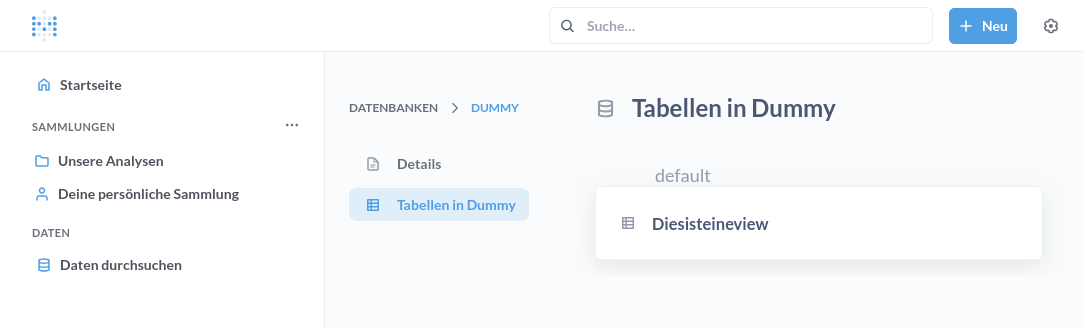
Das in dieser View auf eine Tabelle aus einem Microsoft SQL Server und eine Tabelle aus einem MySQL Server zugegriffen wird, ist nicht ersichtlich. Stattdessen kann die UI im vollen Umfang verwendet werden oder in SQL konvertiert werden.
